Utilisation des scripts de la collection "Omero Bulk Annotation Tools"
Attention
ATTENTION: ces scripts sont encore dans un état de finition laissant à désirer et sont donc très mal documentés.
Ils se trouvent à l'adresse suivante: https://github.com/mpievolbio-scicomp/obat
Un tutorial original (en anglais) se trouve à cette URL: https://github.com/mpievolbio-scicomp/obat/blob/master/readme.orig.md
Un autre tuto se trouve ici: https://mpievolbio-scicomp.pages.gwdg.de/blog/post/2020-09-03_omerobulkannotation/
Ces scripts sont accessibles par l'icône des scripts (engrenage mécanique)
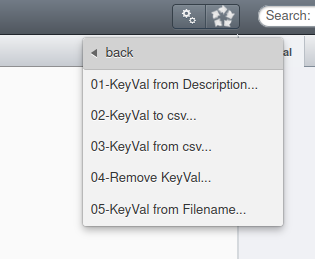
Cette collection comprend 5 scripts:
- 01-KeyVal from Description...
- 02-KeyVal to csv...
- 03-KeyVal from csv...
- 04-Remove KeyVal...
- 05-KeyVal from Filename...
Avant de chercher à utiliser ces scripts, il conviendra de savoir que les virgules sont utilisées comme séparateur. Par conséquent, elles ne devront PAS être utilisées dans les noms des fichiers (que ce doit sous OMERO ou hors OMERO) ou à l'intérieur des champs de valeurs du fichier. Ainsi, en cas de passage d'un fichier CSV en paramètre, elles ne devront PAS être utilisées en dehors de la séparation des champs de valeur.
"01-KeyVal from Description..."
Un tuto plus détaillé (en anglais) pour ce script est à cette adresse: https://code.research.uts.edu.au/MIF/OMERO-instructions/-/wikis/organising_data/Adding-Global-Key-Values
En sélectionnant ce script, la fenêtre suivante s'affiche:
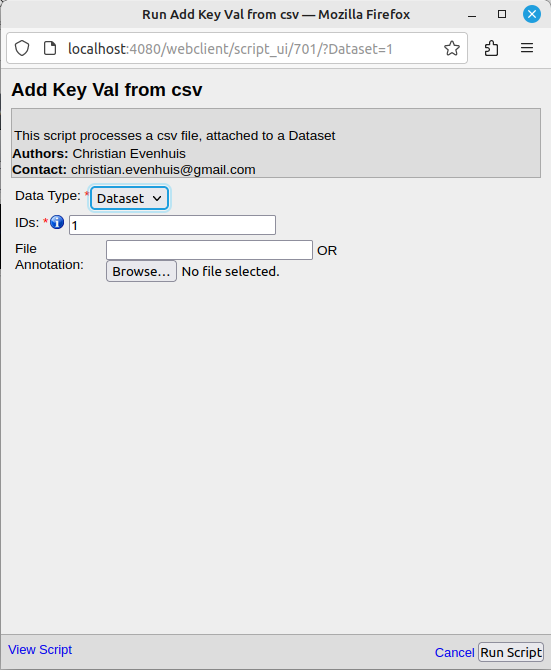
La liste déroulante "Data Type" permet de sélectionner le type de données concernées. Il n'y a en réalité pas de choix. Ce script ne s'applique qu'aux datasets OMERO.
Le champ "IDs" permet d'entrer les numéros des datasets sur lesquels appliquer l'opération.
Ce script s'applique a un dataset. Il permet d'ajouter des informations figurant dans la description en tant que paires clés/valeurs. Ces informations doivent être sous la forme suivante:
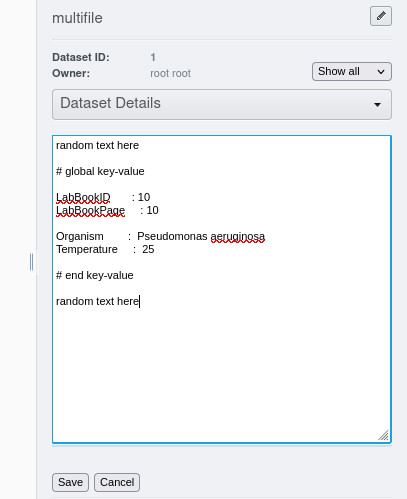
# global key-value
LabBookID : 10
LabBookPage : 10
Organism : Pseudomonas aeruginosa
Temperature : 25
# end key-value
Les informations à ajouter devront figurer entre les 2 balises "# global key-value" et "# end key-value". Elles devront être sous la forme "clé:valeur" séparés par le caractère ":" (les espaces figurant dans l'exemple sont facultatifs).
Cliquer sur "Run Script" pour lancer le script.
"02-KeyVal to csv..."
Ce script s'applique à un dataset. Il permet de convertir les paires clés/valeurs ("Key-Value Pairs") des images du dataset (pas du répertoire du dataset) en un fichier de texte brut au format CSV.
En sélectionnant ce script, la fenêtre suivante s'affiche:
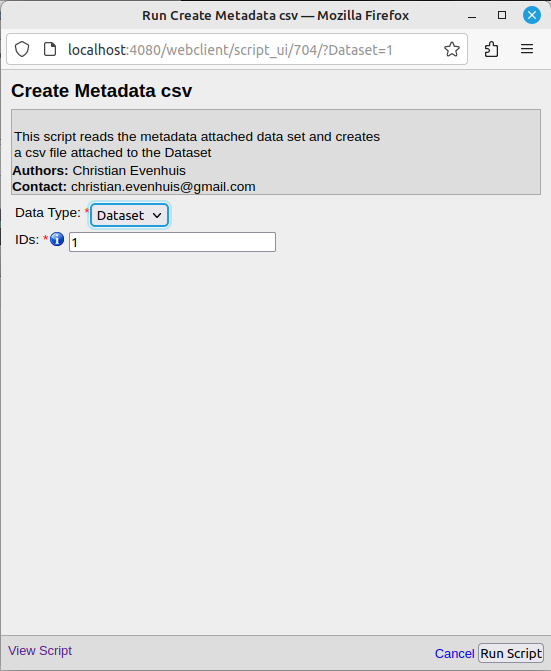
La liste déroulante "Data Type" permet de sélectionner le type de données concernées. Il n'y a en réalité pas de choix. Ce script ne s'applique qu'aux datasets OMERO.
Le champ "IDs" permet d'entrer les numéros des datasets sur lesquels appliquer l'opération.
Cliquer sur "Run Script" pour lancer le script. Le fichier CSV apparaîtra en tant que pièce jointe ("Attachment") au répertoire du dataset, sous le nom "multifile_metadata_out.csv".
"03-KeyVal from csv..."
En sélectionnant ce script, la fenêtre suivante s'affiche:
Ce script s'applique à un dataset. Il permet d'associer les valeurs d'un fichier CSV attaché au dataset (dans la rubrique "Attachments") aux images du dataset.
Le contenu du fichier CSV devra être sous la forme suivante:
filename, number_of_satanic_invocations
image_0.czi, 666
La colonne "filename" est obligatoire. La deuxième colonne n'est là que pour donner un exemple de valeurs, pour ceux qui n'auraient pas compris.
La liste déroulante "Data Type" permet de sélectionner le type de données concernées. Il n'y a en réalité pas de choix. Ce script ne s'applique qu'aux datasets OMERO.
Le champ "IDs" permet d'entrer les numéros des datasets sur lesquels appliquer l'opération.
Le champ "File Annotation": permet d'entrer le numéro d'"Annotation ID" du fichier CSV ajouté en pièce jointe. Il est possible d'obtenir cette valeur en positionnant le pointeur de la souris dur le nom du fichier dans la liste de pièces jointes. Noter que cette façon de procéder NE PERMET PAS d'associer le contenu d'une pièce jointe d'un autre dataset.
Le bouton "Browse" sert théoriquement à sélectionner un fichier présent sur le disque dur de votre ordinateur. Ce bouton n'est pas fonctionnel (les scripts sont encore en état expérimental).
Cliquer sur "Run Script" pour lancer le script.
"04-Remove KeyVal..."
Ce script permet d'enlever tous les dictionnaires des images d'un dataset, et du dataset lui-même.
En sélectionnant le script, la fenêtre suivante s'affiche:
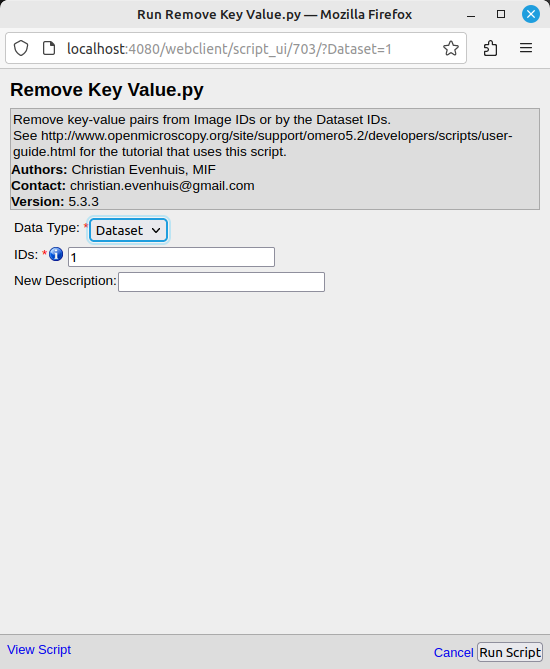
La liste déroulante "Data Type" permet de sélectionner le type de données concernées. Il est possible de choisir entre Dataset et Image.
Le champ "IDs" permet d'entrer les numéros des datasets sur lesquels appliquer l'opération.
Le champ "Descriptions" permet théoriquement d'entrer une nouvelle description pour chaque image du dataset (dans le cas d'un Dataset) ou pour l'image sélectionnée (sans le cas d'une Image), mais ne fonctionne pas.
Cliquer sur "Run Script" pour lancer le script.
"05-KeyVal from Filename..."
Un tuto en anglais pour ce script est à cette adresse (servant de base au tuto ci-dessous): https://code.research.uts.edu.au/MIF/OMERO-instructions/-/wikis/organising_data/filename/Extracting-Key-Values-from-filenames
En sélectionnant ce script, la fenêtre suivante s'affiche:
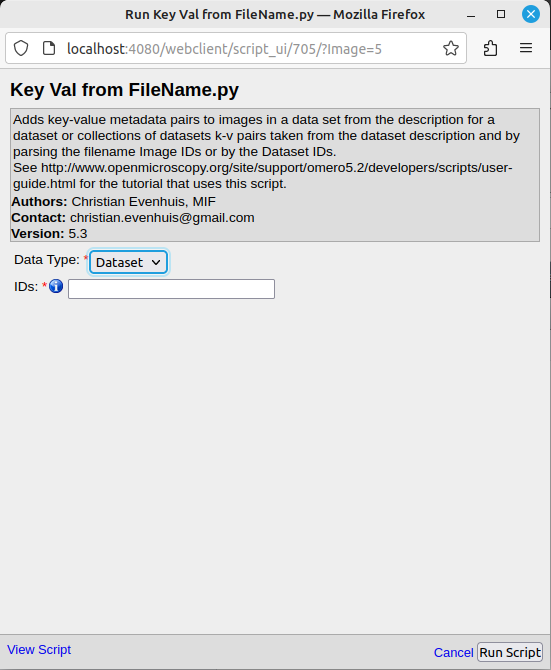
La liste déroulante "Data Type" permet de sélectionner le type de données concernées. Il n'y a en réalité pas de choix. Ce script ne s'applique qu'aux datasets OMERO.
Le champ "IDs" permet d'entrer les numéros des datasets sur lesquels appliquer l'opération.
Ce script effectue les opérations suivantes:
1: Récupère un schéma d'organisation des informations dans le nom du fichier (template) qui sera ajouté en description 2: Récupère les numéros associés à chaque information, qui seront ajoutés en description 3: Découpe les noms des fichiers selon le template de l'étape 1 pour en extraire les infos, et associe chaque info à la clé associée selon leur position dans le nom de fichier, puis stocke les paires clé/valeur en tant que métadonnées.
Voici un exemple de démonstration:
Exemple de titre: "150707_FishNewProbes_TRITC_Eurb388_01_snapshot_R3D.dv"
Dans cet exemple, le séparateur est clairement le caractère "_" (Underscore). Il est possible d'utiliser d'autres caractères.
Les informations nécessaires au parsing du nom de fichier seront ajoutées en description de cette façon:
# filename key-value
template *_*_*_*_*_snapshot_R3D.dv
1. DateOfExperiment
2. Probe used
3. FilterSet
4. GeneInsert
5. Replicate
# end key-value
Les informations à ajouter devront figurer entre les 2 balises "# filename key-value" et "# end key-value". D'abord le template, puis les numéros/clés. Respecter la syntaxe du template (utiliser le caractère "*" pour représenter les informations entre chaque séparateur).
Le moyen le plus simple pour écrire le template est de copier un nom d'un des fichiers dans la boîte de description, puis de remplacer chaque partie importante du nom par un astérisque. En dessous écrire les numéros/clés (par exemple, "1.", suivi du nom de la clé, puis incrémenter).
Cliquer sur "Run Script" pour lancer le script.